知源-数据资产地图系统
知源-数据资产地图系统 知影-API安全管理平台
知影-API安全管理平台 知镜-数据安全检测工具
知镜-数据安全检测工具 一站式-数据安全管理平台
一站式-数据安全管理平台 数据出境-合规治理平台
数据出境-合规治理平台 数据安全咨询-服务
数据安全咨询-服务 数据安全评估-服务
数据安全评估-服务 数据安全测评-服务
数据安全测评-服务 数据安全认证-服务
数据安全认证-服务 轻量合规服务-DiRM
轻量合规服务-DiRM 数据安全治理综合方案
数据安全治理综合方案 数据安全分类分级方案
数据安全分类分级方案 内部人员数据风险管理方案
内部人员数据风险管理方案 黑灰产及护网API安全方案
黑灰产及护网API安全方案 数据安全风险评估解决方案
数据安全风险评估解决方案 数据安全咨询服务规划方案
数据安全咨询服务规划方案 政务数据共享安全解决方案
政务数据共享安全解决方案 保险业数据安全解决方案
保险业数据安全解决方案 运营商数据安全解决方案
运营商数据安全解决方案 互联网数据安全解决方案
互联网数据安全解决方案 教育行业数据安全解决方案
教育行业数据安全解决方案news
技术分享


Part 1 FastText 背 景
FastText是Facebook开发的一款快速文本分类器。提供简单而高效的文本分类和表征学习的方法,效果比肩深度学习而且速度更快。Facebook在2016年提出文本分类的方法,摘要中写道,“以准确率与深度学习不分伯仲为前提,在多核CPU中,10分钟内训练10亿词,1分钟内对31.2万类别的50万条语句进行分类”。由此可见相较于深度学习,FastText的训练及测试速度快了几个数量级。

Part 2 技 术 要 点
FastText的模型结构如图所示:
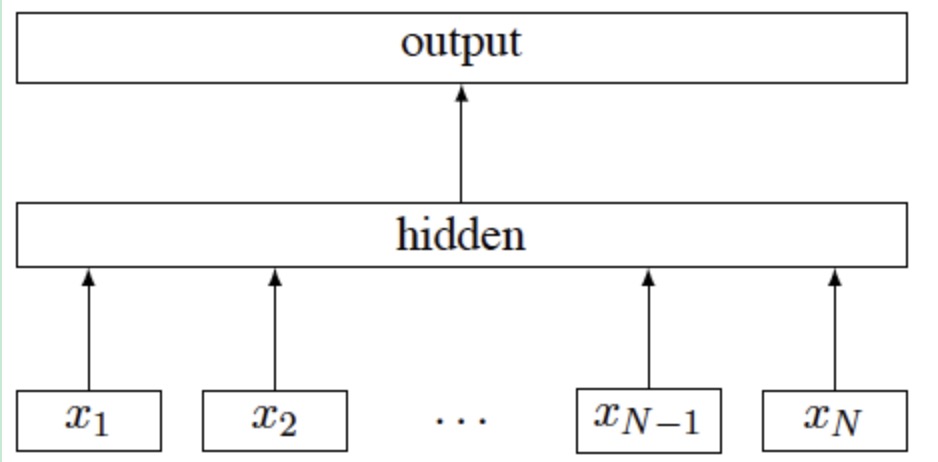
FastText的模型架构主要包括输入层,隐层和输出层。下面我们展开来分别说明每层的具体实现。
输入层:该层叠加了分词和N-gram思想,以在分类分级中的应用为例,如下图,“贷款意向名单担保人信息表”为一条语句,我们先用结巴分词获得分词结果,这里我们设定N-gram=2,因此得到下面的结果;由于分类分级的词库增加了N-gram部分,因此词库的数量会更为庞大,读入隐层前先输入到Embedding层,设定该层的维度=100,从该层输出的内容即为输入层的内容,也即模型结构中的Xi;
·

隐层:输入层的输出中,每个词都对应固定长度的向量,设定语句的固定长度为500维,则如“贷款”对应了1个100维的向量,每条语句对应了500维*100维的向量矩阵,在隐层中,将对该向量矩阵作“平均”,设定500维为行,100维为列,即对每列作“平均”,得到的100维的向量作为该语句的特征表示;
输出层:背景中我们提到fastText在速度上有几个数量级的优势,其原因就在输出层,这里用到的技巧为“分层softmax”;在语料的预处理时,我们根据类别的频率排序,借助霍夫曼树的思想将每个类别添加到树中,类别频数越大,距离树根越近,理论上,分类的时间复杂度由O(N)降至O(log(N)),实际应用中,由于频繁出现的类别占的比重更高,时间效率会远低于O(log(N))。
Part 3 分 类 分 级 中 的 应 用
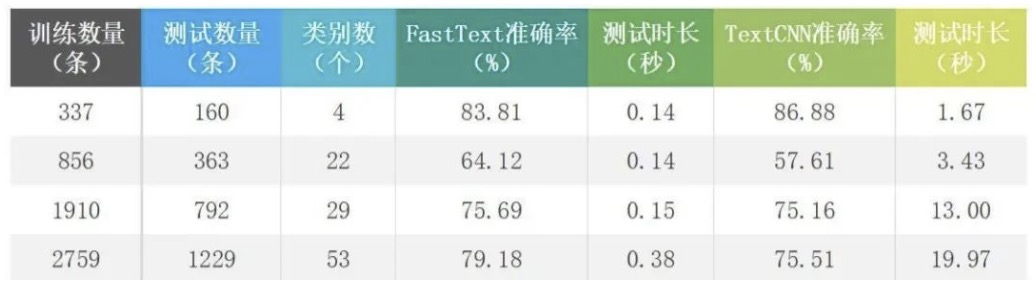
FastText 中的几个超参数需要在实际应用中进行设置,主要的有学习率,训练轮数,N-gram值。作为对比,全知科技对深度学习TextCNN在相同训练/测试数据集下进行测试,其中CNN部分使用2层卷积,卷积核分别为2*2,3*3。以下为某应用数据下不同数据量的实验结果;由下表可知,在数据量较小,如337条数据,fastText的准确率为83.81%,而TextCNN在准确率为86.88%,相差 3个点,随着数据量的增大,FastText的准确率指标逐渐超过TextCNN,根据趋势可以合理推测,两种方法在应用数据下的准确率不分伯仲;而在不同数据量的测试时长上,fastText的测试速度超过TextCNN 10倍有余,如1910条训练数据下,测速时长之比超过80倍。因此,FastText在应用数据中同时,具有测试速度快和精度高的优势。即,以FastText作为分类分级应用的基准模型在实践中是可行的。全知科技将该机器学习算法作为高效算法之一,应用在数据分类分级的服务领域当中。