 知源-数据资产地图系统
知源-数据资产地图系统 知影-API安全管理平台
知影-API安全管理平台 知镜-数据安全检测工具
知镜-数据安全检测工具 一站式-数据安全管理平台
一站式-数据安全管理平台 数据出境-合规治理平台
数据出境-合规治理平台 数据安全咨询-服务
数据安全咨询-服务 数据安全评估-服务
数据安全评估-服务 数据安全测评-服务
数据安全测评-服务 数据安全认证-服务
数据安全认证-服务 轻量合规服务-DiRM
轻量合规服务-DiRM 数据安全治理综合方案
数据安全治理综合方案 数据安全分类分级方案
数据安全分类分级方案 内部人员数据风险管理方案
内部人员数据风险管理方案 黑灰产及护网API安全方案
黑灰产及护网API安全方案 数据安全风险评估解决方案
数据安全风险评估解决方案 数据安全咨询服务规划方案
数据安全咨询服务规划方案 政务数据共享安全解决方案
政务数据共享安全解决方案 保险业数据安全解决方案
保险业数据安全解决方案 运营商数据安全解决方案
运营商数据安全解决方案 互联网数据安全解决方案
互联网数据安全解决方案 教育行业数据安全解决方案
教育行业数据安全解决方案news
技术分享

数据风险全知道
上篇文章《如何让正则表达式性能提升40倍》提到了Hyperscan性能相较于PCRE的优势。下面笔者通过翻译Hyperscan原论文《Hyperscan: A Fast Multi-pattern Regex Matcher for Modern CPUs》来向大家介绍Hyperscan内部实现的原理及算法。
背景
Hyperscan需要运⾏在⽀持SIMD指令集的Intel Modern CPU上比如(SSE,AVX等);SIMD主要是⽤于加速指令运⾏,其加速原理在于,可以并⾏执⾏多条时序无关的指令。如图所示:
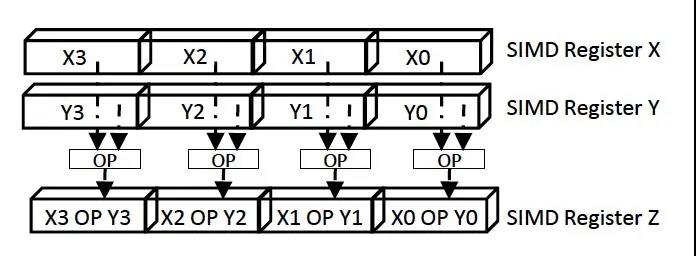
图 | 1 SIMD并⾏执⾏示意
因为Intel推出了并⾏执⾏的指令,再加上正则使⽤之⼴泛,论⽂通过改进现有正则匹配的算 法以及使⽤SIMD技术来达到⼤幅提升正则匹配性能的效果。
Hyperscan实现的核心思想为:1.分解原有正则表达式为多个组件;2.对各个组件匹配算法进⾏改进使其能利⽤SIMD指令。
接下来分别对分解算法及改进算法分别介绍。
正则表达式分解
hyperscan正则分解的主要思想是对正则进⾏拆分,拆分为没有交集的string和sub-regex (FA),此处的FA即Finite Automata有限状态机。
线性正则分解
1:regex —> left str FA
2:left —> left str FA | FA
其中str,FA都是独⽴的组件,FA可以为空。
通过分解⼀个正则可以分解为如下形式:FAnstrnFAn−1strn−1 . . .str2FA1str1FA0
可选择正则分解
形如(A|B),只有当A和B分别可以分解成str或者FA,否则将(A|B)当做⼀个FA进⾏处理 分解完成后,可以使正则的结果与原来的结果保持等价;(数学证明Hyperscan⽬前还未给出)
实现方法
对于正则的分解,采⽤基于图的分解方法分为三种 :
1.路径分析
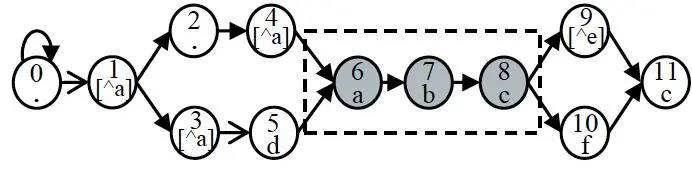
图 | 2 路径分析
2.区域分析
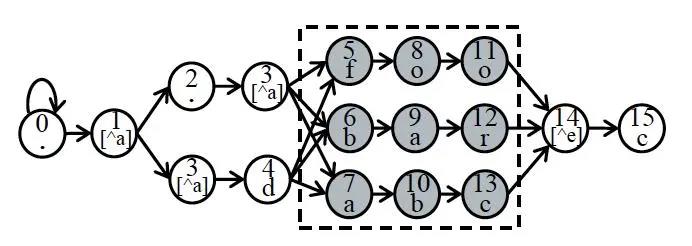
图 | 3 区域分析
3.网络流分析
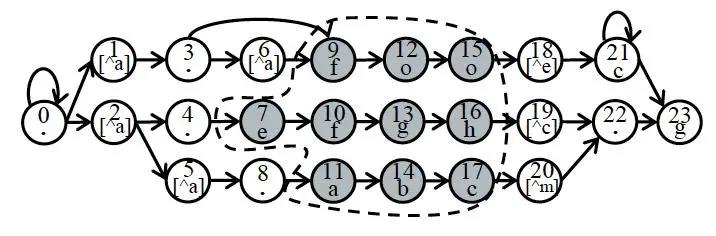
图 | 4 网络流分析
SIMD-Acc正则匹配
该章介绍multi-string及FA匹配算法,该算法利⽤SIMD进⾏加速。
multi-string匹配算法
该算法名称为FDR;算法分为两个步骤,如图:
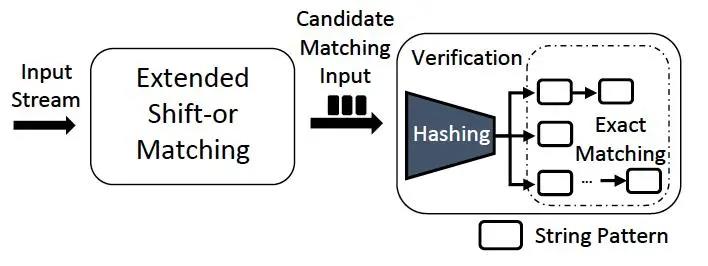
图 | 5 FDR匹配的两个阶段
⾸先采⽤Extended Shift-or Matching算法对已经分解的Str进⾏匹配;对于已经匹配的候选项再交由FA匹配算法进⾏匹配。
Shift-or Matching
shift-or Matching算法是⼀个简单的算法;如图:
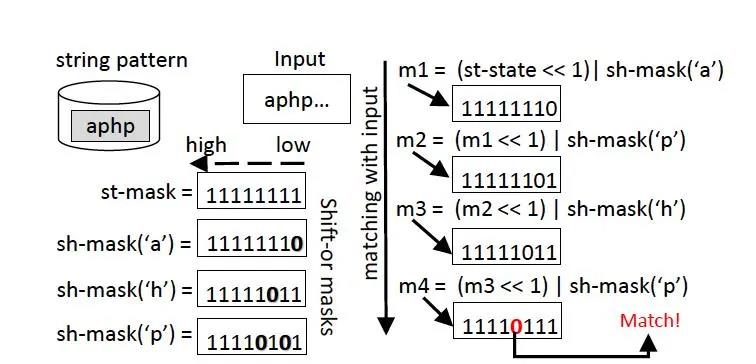
图 | 6 经典shift-or matching算法
对于需要匹配的字符串,需要维护两个状态st-mask,及sh-mask(‘c’);
对于候选的匹配字符串,如果’c’在字符串中,那么sh-mask(‘c’)的bit位除了对应其出现再字符串的位置为0外其他位都为1;
如图6中,匹配字符串为”aphp”,’p’出现在了字符串的第2及4位,那么sh-mask(‘p’)=11110101
st-mask初始状态为11111111
对于新的字符输⼊‘x’:
st-mask=((st-mask≪1) | sh-mask(‘x’)
当st-mask的匹配字符串长度对应的bit位为0则表示匹配成功了。
shift-or Matching算法有比较高的运行效率。但同时存在两个缺点:1.只支持单个字符串的匹配;2.不能使⽤SIMD指令进⾏提效。
为了克服这两个缺点,使用算法如下:
Multi-string shift-or matching
为了⽀持多字符串的同时匹配,修改了数据结构。
⾸先,将字符串划分到n个bucket中,每个bucket编号为0-n-1;假设,每个字符串只属于⼀个bucket;
第⼆步,将st-mask及sh-mask扩⼤n倍;
sh-mask(‘x’)初始化为全1 ;
如果’x’出现在了第n个bucket的第k位,那么sh-mask(‘x’)第k个位置上的第n为置位0;同时对于长度小于最大的字符串长度的bucket,需要增加补充位。
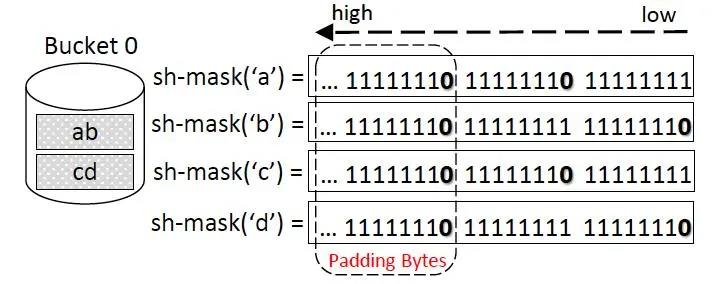
图 | 7 sh-mask示例
此处的第k个位置和shift-or Matching算法的区别,在于此处从右边开始计数;st-mask |= (sh-mask(‘x’) ≪ (k bytes))。如下示例
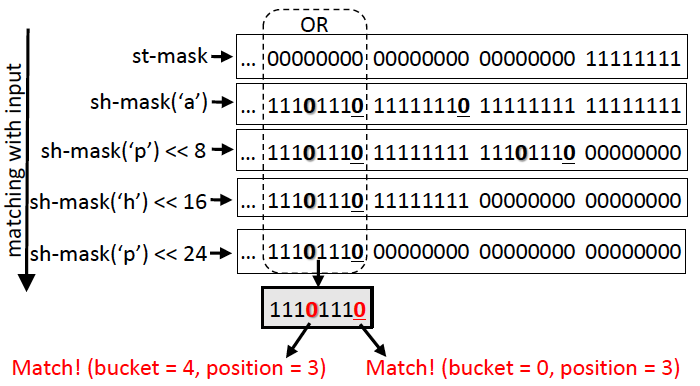
图 | 8 FDR Multi-string shift-or Matching
模式分组
上文提到需要将一对字符串分配到不同的group中;本文采用动态规划的方法进行分组。
首先根据字符串的长度对字符数组进行排序;然后利用如下动态规划方程完成分组:
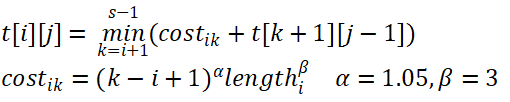
算法改进
对于同一个bucket中的编码,存在一定的缺陷。如示例图7中,因为a,c等价,b,d等价;那么会把ad,cb也误识别;此处为了修正该bug对算法进行改进;即内部字符采用扩充长度的方式,将字符长度扩大到m位(9≤m≤15)
假设m=12 那么a映射为a=((loworder4bitsofb<<8)|a)
SIMD提速
经过以上改进后,各个组件可同步使用SIMD指令进行提速。
有限状态机正则匹配
String matching成功后,将会触发FA Matching;FA Matching为了能够有效的利用SIMD提速,采用bit based-NFA的方式进行运行。算法描述如下:
首先对NFA的n个状态进行编码0,n-1;
定义状态S,表示当前各个状态的有效性;比如第k位为1,则表示当前第k个状态是有效的;
定义shift-k mask,表示当前状态对于新输入的节点可以略过k个状态达到新的状态;
Exception mask表示的是处于exception节点的标志
succ_mask[i]表示i节点能达到的节点集合(bit设置为1,表示能通过一次转换达到该状态);
reach[x],表示字符k可能达到的所有状态;
状态转换定义为类型节点及例外节点;类型节点状态转移跨越节点数<=k,并且没有往回走的状态。
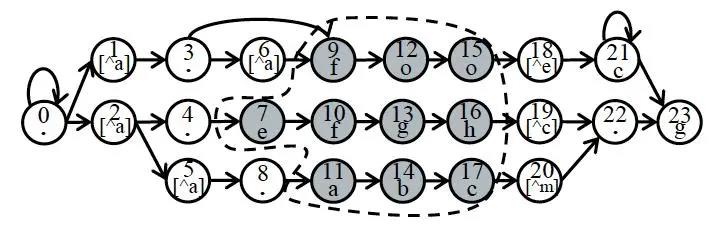
图 | 9 正则(AB|CD)AFF*的NFA展示
如图9所示,shift-k设置为2;其中0,2,4位例外节点;算法描述如下:

- END -
如有侵权,请联系删除


.png)


