 知源-数据资产地图系统
知源-数据资产地图系统 知影-API安全管理平台
知影-API安全管理平台 知镜-数据安全检测工具
知镜-数据安全检测工具 一站式-数据安全管理平台
一站式-数据安全管理平台 数据出境-合规治理平台
数据出境-合规治理平台 数据安全咨询-服务
数据安全咨询-服务 数据安全评估-服务
数据安全评估-服务 数据安全测评-服务
数据安全测评-服务 数据安全认证-服务
数据安全认证-服务 轻量合规服务-DiRM
轻量合规服务-DiRM 数据安全治理综合方案
数据安全治理综合方案 数据安全分类分级方案
数据安全分类分级方案 内部人员数据风险管理方案
内部人员数据风险管理方案 黑灰产及护网API安全方案
黑灰产及护网API安全方案 数据安全风险评估解决方案
数据安全风险评估解决方案 数据安全咨询服务规划方案
数据安全咨询服务规划方案 政务数据共享安全解决方案
政务数据共享安全解决方案 保险业数据安全解决方案
保险业数据安全解决方案 运营商数据安全解决方案
运营商数据安全解决方案 互联网数据安全解决方案
互联网数据安全解决方案 教育行业数据安全解决方案
教育行业数据安全解决方案news
技术分享

中共中央、国务院2020年3月30日公开发布了《关于构建更加完善的要素市场化配置体制机制的意见》(以下简称《意见》),在意见的第六章中,就数据作为生产要素提出了明确意见。

将数据作为生产要素,在社会上的探索已经开展多年了。 以贵阳为核心的贵州省对大数据产业进行了探索,BAT等网络服务商、电信与网络运营商等近几年也都有不错的建树和积累,同时,对数据在生产过程中的安全也有不少探索,比如DSMM数据安全能力成熟度模型国家标准;全知科技(杭州)有限责任公司提出了“数据作为生产资料”和“数据在生产过程中”的安全观点及相关解决方案等。这些都是非常有意义的探索,可以作为对数据生产要素研究工作的基础。
实际上,早在2016年,笔者在贵阳探索“大数据安全的顶层设计”时,就已经开始遇到了这样的问题。当时在对大数据的挖掘中,发现了基于数据安全属性的访问控制将失效,利用大数据挖掘,可以发现个人隐私,通过已知数据,可以推导出未知数据等带有生产性质的问题,但是当时还没有明确将数据作为生产要素,也没有从数据作为生产要素这一命题出发来思考,也不够系统化。
1
数据作为生产要素的思考
1.1
数据与其他生产要素的关系
劳动力(或劳动能力) ,是“人的身体即活的人体中存在的、每当人生产某种使用价值时就运用的体力和智力的总和”。
劳动资料(也称劳动手段) ,是劳动过程中所运用的物质资料或物质条件。
劳动对象, 即劳动过程中所能加工的一切对象,包括自然物和加工过的原材料。
而五大生产要素本质是生产力的构成:人、物(土地)、财(资本)、技(知识)、数,自古以来都有。“劳动力”是人,“劳动资料”是物、财、技、数,“劳动对象”是物、财、技、数,只是当社会发展到一定阶段才成为单列必要。比如狩猎时代生产要素只有人;农耕时代突出了土地;工业时代突出了资本和技术;而数字经济时代突出了“数据”,所以《意见》中的观点,本质上是人类社会发展到新阶段的“生产力范围延伸”。
数据与其它要素之间,既具备独立性特点,也存在着明显相互作用。 一方面其他四要素可以作为数据的来源,另一方面数据又可以反作用回其它四要素。同时,这种作用可以是渐变的,也可以是突变。
1.2
作为生产要素的数据的分类与场景分析
数据作为生产要素,可分为若干多的类别,首先从国民经济行业划分。
当然,还有其他很多不同类别的分类方法,去分析数据的类别,进一步研究数据分类角度,对深入理解数据要素是很有意义的。特别是,我们不仅要考虑数据的当前的资产价值,还要考虑数据增值(未来价值)。而对数据增值的分析和评估,也是我们对数据的安全保护所要考虑到的。
数据作为生产要素形成产品可以分为两大类,一类是将数据作为物质资料和物质条件生产的实体类产品;而另一类则是再生的数据类产品;所以组合后可能会有四种基本情况:
2
对数据保护的思考
一个完善的保护体系方案,必须建立在对安全需求充分理解的基础之上。 安全需求,则需要我们对可能的安全事件及影响进行充分的识别。无论是从风险评估体系,还是等级保护体系都面临了相应的挑战。
2.1
数据本身的安全需求分析
从风险分析的观点出发,与风险相关的三个基本因素是: 资产的价值、威胁和脆弱性。
对于作为生产要素的数据,不仅要考虑作为资产的当前价值,还要考虑其增殖价值,如何来衡量,是一个需要解决的问题。风险评估中,对资产价值的赋值是依据数据当前的安全属性,根据其保密性、完整性的安全要求,来决定给其进行相应的赋值。在等级保护中,GB/T22240【参考资料1】也明确提出依据业务信息(指的就是数据)的机密性和完整性进行赋值,以决定数据的安全等级,进而确定所承载系统的安全等级。并且无论是风险评估,还是等级保护我们都是对一个一个的单个数据客体进行这样分析,从中取最高值。
当数据作为生产要素后,我们对数据的赋值,即要考虑当前数据安全赋值,还要考虑这些数据的增殖效应,而这个增殖效应是未来的。并且这个增殖效应是有不确定性的,由于运用这些作为“资料和条件”的劳动力(或劳动力团队)的知识水平、分析判断能力、使用的加工工具等因素的不同,增殖的结果往往会不同,其价值当然也不相同。
并且这个价值的评估,不应该简单仅仅依赖于数据的保密性、完整性,还要考虑这个增殖的结果本身的其他价值,比如对国计民生的意义,对国防的意义等。如何来衡量这个未来的价值,虽然需要结合到具体的数据集群,劳动力集群等进行分析评估,但是最终应该给出一个相应指导方法来才行。
在以将数据作为资产来保护时,我们是对单个数据进行这样的赋值的,而对于作为生产要素的数据往往是一个数据集群,单个数据的价值并没有那么大。
数据的增值价值,还体现在共享这些数据劳动力(或者是劳动力团队)。有一种说法,数据越共享,产生的价值越大。我们先不讨论这一命题,需要分析的是,数据共享出去以后,共享团队所产生的增殖价值,对当前团队的意义是什么,对当前团队的利益是增加,还是受到侵害。这就不可能不涉及到共享范围和对共享对象的评估问题了。
作为风险的第二个因素,是对威胁的分析,威胁源与应用的场景是密不可分的。对于作为资产进行的保护,我们可以用隔离的办法,将相当一部分威胁源隔离出去。而对于作为生产要素的数据来说,这种隔离是不容易实现的。并且由于共享的团队的加入,会导致威胁源的攻击入口增加。
2.2
数据技术衍生的安全风险
利用生产,是可能生产安全风险的,主要是利用已知条件,推导出未知因素。主要是两大方面,一是个人隐私的泄露问题,另一类是敏感信息的泄露。
利用已知推导未知是大数据的普遍的分析方法,这也是一个生产过程。
利用导航定位数据为一个人的活动进行画像,并不是一件困难的事情;通过手机联系人的关联,很容易分析一个人的朋友圈等。如果这些仅仅是为了商业利益,并且有适度的管控,问题还不大。但是,如果被恶意利用,就可能导致重大的安全问题。有人说,“把大数据利用得最好的是诈骗犯”是有一定的道理的。
同样利用已知的公开数据,是有可能推导出一个机构的未知数据的,如果是这个机构的敏感数据,那么对这个机构来说威胁就大了。
3
安全解决方案的思考
3.1
负信任的问题
3.2
安全解决方案的思考
【参考资料2】中,还给出了一个七步的RPCMART安全模型,参考资料3中了提到了生产安全和生态安全问题。本文暂不进一步展开解读这些内容,而是要提出我们对安全解决方案的一些思考,当然这只能还是停留在思考的层面上,还不是一个完整的解决方案体系。
在现实社会中,一个生产型的企业,会将原料、半成品、加工车间和成品分区分域的进行管理,相应的库房也是材料库,半成品库,成品库等,这样就非常方便的进行管理了。并且材料库还可以再细分一般性的原材料库和重要的原材料库,加工原料,是要有相应的“领料”手续的,而在生产过程中,还要有过程上的管理,包括质量的管理和材料的管理,甚至有些“废料”都是要进行管理的。
网络空间的安全的规则和方法,可以认为是现实社会安全规则与方法在网络空间中的映射,相应的对于“数据作为生产要素”我们也完全可以参照现实社会中的一些规则和方法进行分区管理。
我们建议按照图1的方式作基本的分区:
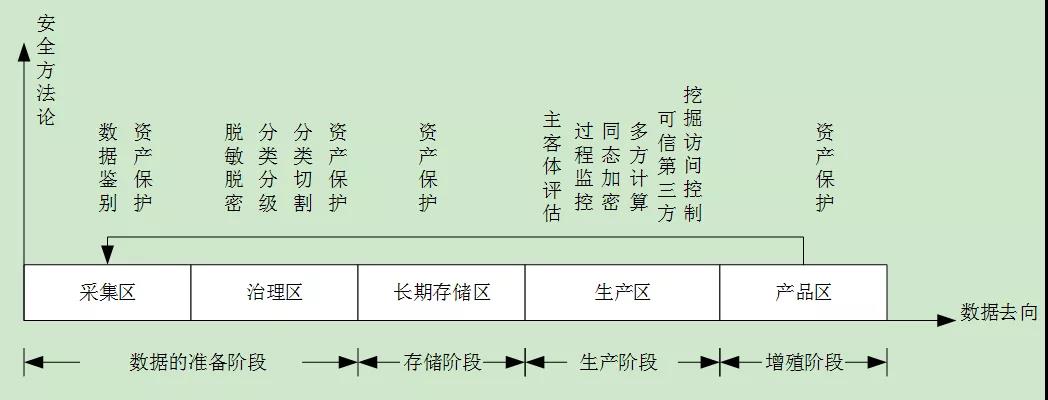
图1:数据的分区管理及基本的安全方法
对于数据的其它区域,仍然可以按照数据是资产这一思想进行保险柜式的保护,相应的国家的等级保护制度及相关的各类安全标准,是能够解决。我们讨论一下生产区安全方案的几个重点问题:
对主客体的评估。对于客体的评估,一是要考虑到当前的价值,二是要考虑增殖价值,而增殖价值,不能简单的依据数据的安全属性进行分析,还要考虑这个数据集群整体蕴含的价值,还要考虑这个蕴含的价值,会对国家安全、经济建设、公众利益、社会秩序、公民与法人的利益产生的影响。
对主体的评估,主要是分析这些主体将当前的数据集群作为生产资料时的目的,及这些主体团队的背景等进行分析,去年出台的关于DSMM的国家推荐标准《信息安全技术数据安全能力成熟度模型》(GB/T37988-2019)可以作参考。
对生产过程的监控, 我们将在3.2.2中进一步说明。
隐私计算场景。 同态加密、多方计算等方式的引用,可信第三方的引入,使得数据可用而不可见。数据挖掘的访问控制模型,这是一个还没有公开发表的模型,是TBAC的改造模型,目的也是数据的可用而不可见。
在将数据作为资产进行保护的情形下,计算环境中一个非常重要的安全模块是访问监控器 【参考资料4】 ,这是在操作系统安全子系统的核心,许多应用程序,也会参考这个模型进行设计具体应用的访问控制问题。如图2a,但是这个访问监控器,只能做到一个主体访问一个客体,而对于将数据作为生产要素的生产过程,这个访问监控器将无法完成相应的监控和授权机制。为此笔者提出了图2 b的思路。
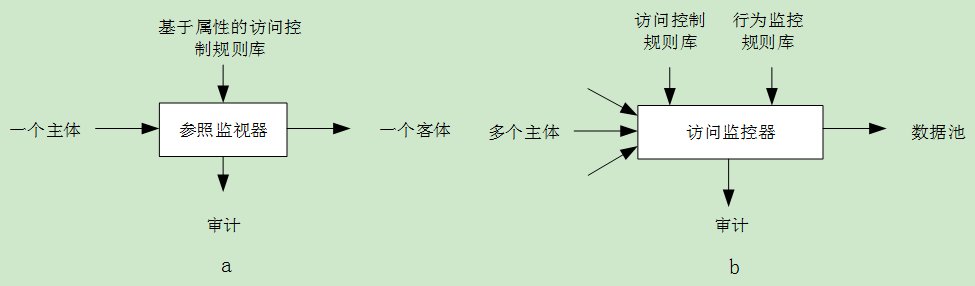
图2:生产过程中的对数据加工的监控和管理
首先访问控制规则,在图2b中,是不可能规划成细粒度的,经过对主体评估后,应该允许这个主体(可以是用户也可以是用户组),对数据池(数据集群中的子集或者是全部)具有访问的权力,当然,数据池可以是数据集群的全部,也可以是一个子集。导入到生产用的数据池中的数据,应该是经过各种治理过的数据。
4
结语
人类正在加速进入新的数据时代,自古有之的数据正在成为社会核心生产要素,所以需要体系化的构建数据新要素,包括理论和实践。
本文分别从数据要素、数据安全、整体安全等方面提出一些思考,探索将数据作为生产要素情形下的安全体系设计。我们的目的是引起产业对数据作为生产要素情形下的安全体系设计的关注,逐步形成相对完善的数据生产要素安全体系。
【参考资料1】:《信息安全等级保护定级指南》(GB/T22220--2006)
【参考资料2】:方兴《数据流动时代大数据风险如何管控》
【参考资料3】:方兴《从生产安全体系视角看数据安全》
【参考资料4】:《操作系统安全2.5.1》(卿斯汉等著清华大学出版社)
作者介绍:





